

Pythonのデータ型とアルゴリズムについてです。
Javaで言うデータ型とAPIあたりでしょうか。前の章に出たジェネレーターもそうで、今回の二分法やイテレーターもそう感じてますが、Pythonはかなりビッグデータを意識した処理の効率化やメモリ使用量が意識された設計になっているように思えます。まあ、ニーズがあった上のカスタマイズかもしれませんが、当然といえば当然ですね。
要点
テキストの「9 データ型とアルゴリズム」の内容について、自分なりにまとめた要点は以下です。
内容は少し多めですが、ご参考になれば嬉しいです。
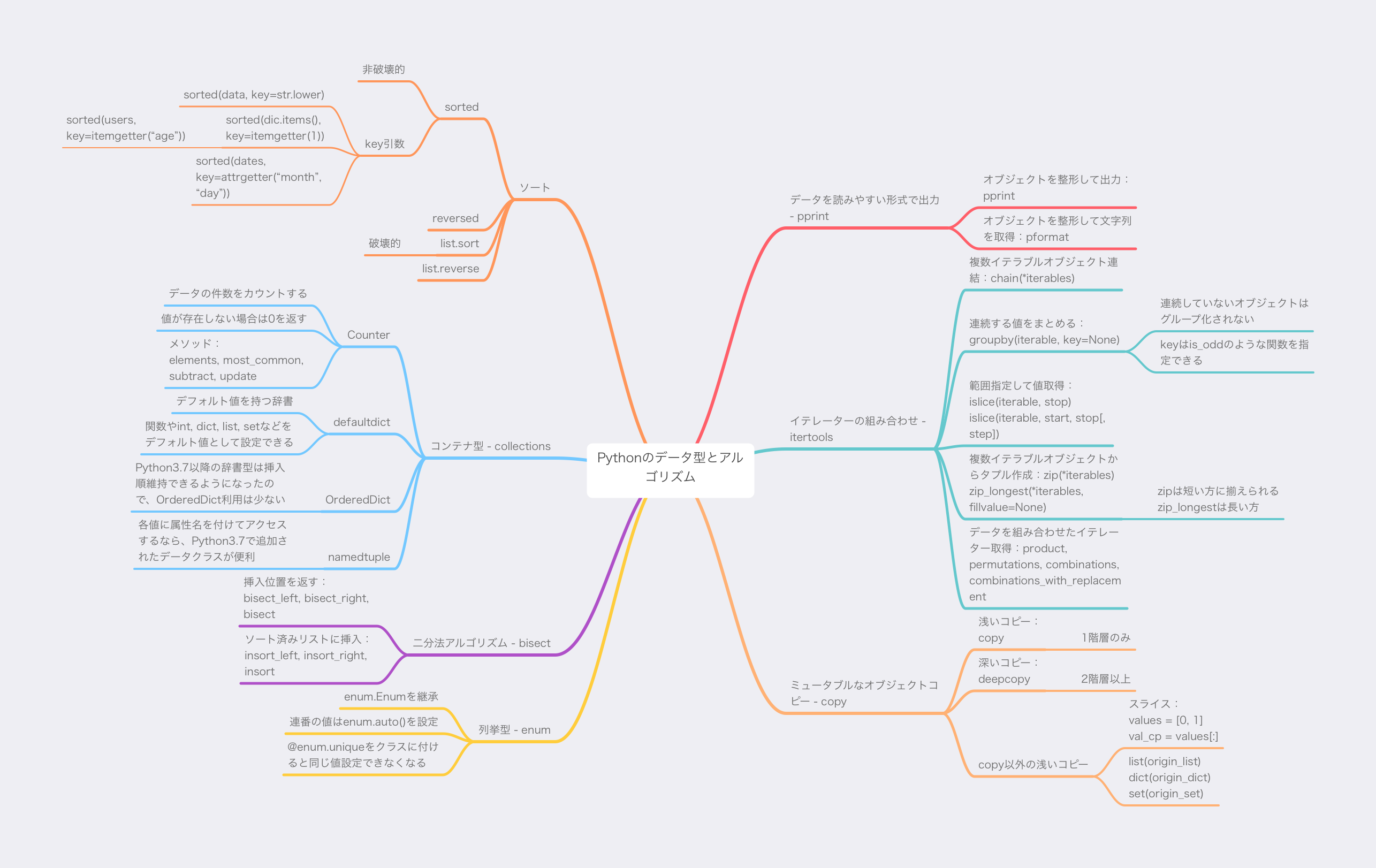
補足と余談
bisectのよくあるエーラと対処法で言及されましたが、bisectは対象となるデータがソートされている前提で挿入位置を計算して返すので、対象データがソートされていないと、正しい挿入位置を取得できません。- enumの連番する値は
enum.auto()設定できるところがありがたいですね。 intertools.groupby('aaabbcdddaabb')を実行すると、最初の’aaa’と2番の’aa’は異なるグループになります。
ここまでの内容で、テキストの半分が終わりました。それに対して試験の申込みしてから試験まで3/5の時間経過しています。ペースはまだ遅いですが、あと一踏ん張りですね!
コメントを残す